Part 1A: Description of the Data
In this next section, we explore two methods, Classification Trees and Random Forests in trying to predict recidivism. First, let's take a look at the data.
Description of the Data
The data being used consists of 10,428 criminals in Broward County, Florida from the years 2013 to 2014 and contains past criminal history and what they were charged for when they were arrested. Moreover, it contains the outcome (recidivated / did not recidivate) after two years of receiving their COMPASS risk assessment. For a description of each variable, please click here.
Classification Trees
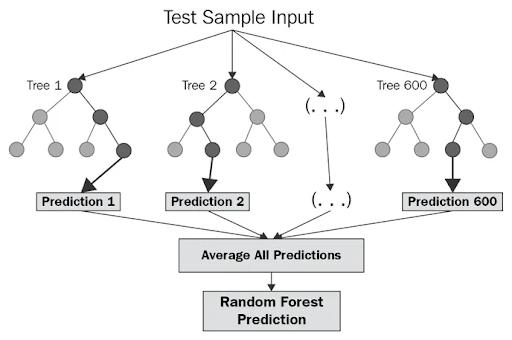
Our first method of machine learning that we will look at are classification trees. To familiarize yourself, please watch the video below that goes through the process of creating a classification tree by using a sample of the data we will be using.
With measuring accuracies, it is also important to measure the accuracy of a model as it relates to different groups. This is a good way to check if the model may be inherently biased towards a specific group.
Part 1B: Recidivism in the United States
Investigating Your Own Classification Tree
Use the app below to make your own Classification Trees. The app allows you to choose which variables go into making a classification tree and how bushy (# number of branches) your tree can be. Also, you can see how well your tree performs by looking at the confusion matrix and overall accuracy. You can also view the accuracy of your tree by race, sex, marital status, and age category.
To use the app below, start with the following settings then answer the questions to the left.
- Past History of the Criminal: priors
- Charactericstics of the Criminal: age sex
- Type of Crime Committed: Null
- See accuracy accross: none